ویرایش محتوا
.
H
C
R
A
E
S

تصور کنید برای اولین بار به یک سازمان بزرگ برای انجام کاری اداری مراجعه کردهاید؛ هیچ کجا را نمیشناسید و مسیرها برایتان ناآشناست. مدیران این سازمان برای اینکه از سردرگمی و هرج و مرج جلوگیری کنند، در ورودی یک باجه اطلاعاتی قرار دادهاند و افرادی را مسئول راهنمایی و نظارت کردهاند. اگر این راهنماها و نگهبانان نباشند، همه بدون نظم در راهروها پرسه میزنند، و کارمندان نیز نمیتوانند وظایف خود را بهدرستی انجام دهند. در وبسایتها، فایل robots.txt دقیقاً همان نقش راهنما و ناظر را برای رباتها دارد، اما نه برای کاربران عادی، بلکه برای رباتهایی که برای ایندکسکردن یا اهداف دیگری به صفحات مختلف سایت سر میزنند. در این مقاله، از آژانس بازاریابی محتوایی مهام به بررسی اهمیت و نحوه عملکرد فایل robots.txt پرداخته و خواهیم دید چگونه میتوان از آن بهعنوان یک ابزار کارآمد برای بهینهسازی ساختار سایت و حفظ حریم خصوصی استفاده کرد.
رباتها در واقع نرمافزارهای خودکاری هستند که به طور مداوم صفحات مختلف وب را باز و بررسی میکنند. در میان این رباتها، رباتهای موتور جستجوی گوگل از اهمیت ویژهای برخوردارند. این رباتها روزانه بارها و بارها به صفحات وبسایتها سر میزنند؛ اگر سایت بزرگی داشته باشید، ممکن است گوگل در طول یک روز تا دهها هزار بار صفحات شما را پیمایش کند.
هر یک از این رباتها وظیفه مشخصی دارند. برای مثال، Googlebot، مهمترین ربات گوگل، وظیفه پیدا کردن صفحات جدید اینترنت و جمعآوری آنها برای بررسی و ارزیابی توسط الگوریتمهای رتبهبندی را بر عهده دارد. در واقع، رباتها نه تنها به سایت شما آسیبی نمیزنند، بلکه حضورشان میتواند ارزشمند هم باشد.
اما نکته اینجاست که این رباتها زبان انسان را نمیفهمند و بدون توجه به محدودیتها، تمامی سایت را زیر و رو میکنند. گاهی ممکن است اطلاعاتی که تمایلی به نمایش آنها ندارید، توسط این رباتها جمعآوری شده و در سرورهای گوگل ذخیره شود. پس لازم است راهی برای مدیریت و کنترل رفتار آنها وجود داشته باشد.
خوشبختانه، با کمک فایل robots.txt میتوان دسترسی رباتها به صفحات یا بخشهای خاص سایت را محدود کرد. با نوشتن دستوراتی ساده در این فایل، میتوانید تعیین کنید که رباتها از کدام قسمتها بازدید کنند یا نکنند. به این ترتیب، علاوه بر کاهش بار غیرضروری روی سرور، وبسایت خود را نیز از منظر سئو تکنیکال بهینهسازی خواهید کرد.
مدیریت رفتار رباتها یکی از جنبههای ضروری در بهینهسازی سایت است که در کنار سئو داخلی و سئو خارجی، به عملکرد بهتر سایت در موتورهای جستجو کمک میکند.
به نقل از سایت: تریبون
فایل Robots.txt مثل یک مجوز دهنده به رباتها است. وقتی رباتها میخواهند صفحههایی از سایت را بررسی کنند، اول فایل Robots.txt را میخوانند.
در این فایل، با چند دستور ساده تعیین میکنیم که رباتها اجازه بازدید از کدام صفحات را دارند و کدام صفحات باید برای آنها غیرقابل دسترسی باقی بماند.
برای مثال، در تصویر زیر، دسترسی رباتها به پوشهای به نام photos و صفحهای به نام files.html را محدود کردهایم.
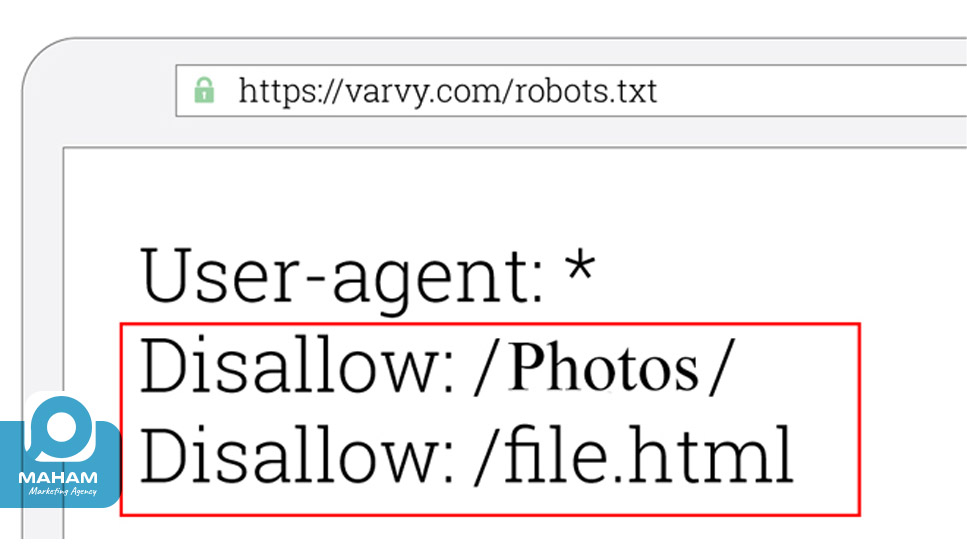
همانطور که گفتیم، مهمترین رباتها در اینترنت، رباتهای موتور جستجوی گوگل هستند؛ بنابراین در ادامه مقاله، هر جا از “ربات” صحبت میکنیم، منظورمان بهطور خاص رباتهای گوگل است.
البته رباتهای دیگری نیز از سوی سرویسدهندههای مختلف اینترنتی وجود دارند. پس از خواندن این مقاله، میتوانید بهراحتی با دانستن نام هر رباتی، دسترسی آن را محدود یا مدیریت کنید.

وبمسترها و صاحبان وبسایت میتوانند دسترسی رباتها به بخشهای مختلف سایت خود را مدیریت کنند، و این کار دلایل متعددی دارد. به عنوان مثال، تمامی صفحات یک وبسایت از درجه اهمیت یکسانی برخوردار نیستند. اغلب وبمسترها تمایلی ندارند که پنل مدیریت وبسایتشان در نتایج موتورهای جستجو نمایش داده شود و برای عموم قابل دسترس باشد. همچنین ممکن است برخی صفحات سایت محتوای مناسبی برای نمایش عمومی نداشته باشند؛ در این صورت، ترجیح میدهند این صفحات توسط رباتها پیمایش نشود.
اگر وبسایتی با تعداد زیادی صفحه و بازدید بالا دارید، احتمالاً تمایلی ندارید که منابع سرور شما (مانند پهنای باند و قدرت پردازش) با بازدیدهای مکرر رباتها به هدر برود.
در این شرایط است که فایل robots.txt به کمک میآید.
هدف اصلی این فایل در حال حاضر، جلوگیری از درخواستهای بیش از حد رباتها برای بازدید از صفحات وبسایت است. یعنی اگر رباتها بخواهند یک صفحه را صدها بار در روز بررسی کنند، میتوانیم با یک دستور ساده در فایل robots.txt به آنها بفهمانیم که “رئیس” کیست و مانع از هدر رفتن منابع سایت شویم.
تا مدتی پیش، اگر قصد داشتید صفحهای را کاملاً از دید رباتهای گوگل پنهان کنید و مانع نمایش آن در نتایج جستجو شوید، میتوانستید از دستور noindex در فایل robots.txt استفاده کنید. اما امروزه شرایط تغییر کرده و این فایل دیگر برای حذف صفحات از نتایج جستجوی گوگل چندان کارآمد نیست.
گوگل توصیه کرده است که برای حذف صفحات از نتایج جستجو، به جای استفاده از فایل robots.txt از روشهای دیگری بهره ببرید. البته همچنان میتوانید از این فایل برای جلوگیری از نمایش فایلهای خاصی مانند تصاویر، ویدیوها یا فایلهای صوتی در نتایج جستجو استفاده کنید، اما این روش برای حذف صفحات وب چندان مؤثر نیست.
در ادامه، برخی روشهای جایگزین برای حذف صفحات از نتایج جستجوی گوگل را معرفی خواهیم کرد.
گوگل مجموعهای از رباتهای خزنده (Crawler) دارد که به صورت خودکار وبسایتها را اسکن میکنند و با دنبالکردن لینکها، از صفحهای به صفحه دیگر، صفحات وب را پیدا میکنند. در جدول زیر، مهمترین رباتهای گوگل و نقش هریک به صورت خلاصه آورده شده است:
| نام ربات | کاربرد |
| AdSense | بررسی صفحات برای نمایش تبلیغات مرتبط |
| Googlebot Image | پیدا کردن و بررسی تصاویر |
| Googlebot News | ایندکس کردن محتوای سایتهای خبری |
| Googlebot Video | بررسی و ایندکس ویدیوها |
| Googlebot (Desktop و Smartphone) | کشف و ایندکس صفحات وب، با نسخههای مخصوص دسکتاپ و موبایل |
این رباتها به صورت مداوم صفحات وبسایتها را بررسی میکنند. در صورت نیاز، امکان محدود کردن دسترسی هر یک از این رباتها به صفحات خاص وجود دارد.
تعداد دفعاتی که رباتهای گوگل از سایت شما بازدید میکنند، به چند عامل بستگی دارد. هرچه محتوای بیشتری در طول روز در وبسایت منتشر کنید و تغییرات سایت مهمتر باشد، رباتها نیز دفعات بیشتری به سایت شما مراجعه خواهند کرد. برای مثال، در سایتهای خبری که دائماً در حال انتشار و بهروزرسانی اخبار هستند، رباتها با سرعت و دفعات بیشتری صفحات را بررسی و ایندکس میکنند.
در سرچ کنسول گوگل، بخشی به نام گزارش crawl stats سرچ کنسول وجود دارد که اطلاعات مفیدی را در مورد دفعات بررسی صفحات سایت توسط رباتها نمایش میدهد. در این بخش، میتوانید حجم دادههای دانلود شده توسط رباتها و همچنین زمان بارگذاری صفحات را مشاهده کنید.
مهام با بیش از 7 سال سابقه در حوزه خدمات سئو، طراحی سایت و سفارش تولید محتوا جز شرکتهای پیشرو در این صعنت، به شما در امر بهینه سازی محتوای سایت برای ربات های گوگل کمک خواهد کرد.
فایل robots.txt به دلایل مختلفی برای وبسایتها اهمیت دارد. در ادامه به برخی از این دلایل اشاره میکنیم:
مدیریت ترافیک رباتها به وبسایت از این نظر مهم است که سرور میزبان وبسایت شما تحت فشار قرار نگیرد و منابع آن تنها بهطور ضروری مصرف شود. بسیاری از سرورها و میزبانها محدودیت پهنای باند و ترافیک دارند؛ بنابراین، جلوگیری از مصرف بیرویه ترافیک برای بازدیدهای مکرر رباتها میتواند به صرفهجویی در هزینهها کمک کند.
با استفاده از فایل robots.txt میتوانید مشخص کنید که برخی صفحات نباید توسط رباتهای گوگل بررسی شوند؛ اما این تنها به جلوگیری از خزیدن آنها توسط رباتها کمک میکند و تضمینی برای عدم نمایش آنها در نتایج جستجو نیست. رباتها ممکن است از طریق لینکهای دیگر به این صفحات دسترسی پیدا کنند و آنها را ایندکس نمایند. برای حذف کامل صفحه از نتایج جستجو، بهترین روش استفاده از دستور noindex در بخش head صفحات است. اگر از وردپرس استفاده میکنید، افزونههای مختلفی برای این کار وجود دارند؛ در غیر این صورت، میتوانید از طراح سایت خود بخواهید این کدها را به صورت دستی در بخش head صفحات اضافه کند.
اگر وبسایت شما صفحات بسیاری داشته باشد، خزیدن و ایندکس کردن تمامی صفحات توسط رباتهای موتور جستجو زمان زیادی نیاز دارد. این مسئله میتواند بر رتبه سایت شما در نتایج جستجو تأثیر منفی بگذارد.
ربات Googlebot دارای مفهومی به نام Crawl Budget است که نشاندهنده تعداد صفحاتی است که ربات در یک روز میتواند در سایت شما بررسی کند. این بودجه بر اساس عواملی مانند حجم وبسایت (تعداد صفحات)، سلامت سایت (عدم وجود خطا) و تعداد بکلینکها تعیین میشود.
Crawl Budget به دو بخش تقسیم میشود. اولین بخش، Crawl Rate Limit (حد نرخ خزیدن) است و دومی Crawl Demand. خب ببینیم معنی هر کدام چیست و چه تاثیری دارند.
ربات گوگل (Googlebot) به گونهای طراحی شده است که “شهروند خوبی” برای اینترنت باشد؛ به این معنا که در حین خزیدن (Crawling) سایتها، تأثیر منفی بر تجربه کاربران نگذارد. این بهینهسازی که به Crawl Rate Limit معروف است، به منظور بهبود تجربه کاربری، تعداد صفحاتی را که در یک روز قابل خزیدن هستند محدود میکند.
به طور خلاصه، Crawl Rate Limit نشاندهنده تعداد دفعات ارتباط همزمان ربات گوگل با یک سایت و توقفهای آن در طی عملیات خزش است. عوامل زیر میتوانند Crawl Rate را تغییر دهند:
حتی اگر ربات گوگل به سقف Crawl Rate نرسد، در صورتی که نیازی به ایندکس کردن صفحات وجود نداشته باشد، میزان خزش کاهش خواهد یافت. دو عامل اصلی در تعیین Crawl Demand (تقاضای خزش) عبارتند از:
علاوه بر این، تغییرات بزرگ سایت مانند انتقال آن به یک آدرس جدید میتواند Crawl Demand را افزایش دهد تا تمامی صفحات سایت مجدداً ایندکس شوند.
در نهایت، Crawl Rate و Crawl Demand با هم میزان Crawl Budget یک سایت را تعیین میکنند. Crawl Budget به تعداد URLهایی اشاره دارد که ربات گوگل قادر است و میخواهد ایندکس کند.
بدیهی است که صاحبان وبسایت مایلند ربات گوگل از Crawl Budget سایتشان به بهترین نحو استفاده کند و بهجای صفحات غیرمهم، روی صفحات ارزشمند و کلیدی تمرکز داشته باشد. گوگل همچنین اعلام کرده است که برخی عوامل میتوانند بر فرآیند خزش و ایندکس سایت تأثیر منفی بگذارند، از جمله:
اتلاف منابع سرور برای این صفحات میتواند باعث کاهش Crawl Budget شما شود و خزش و ایندکس صفحات ارزشمند سایت را به تأخیر بیندازد.
اگر بتوانید یک فایل robots.txt بهینه و کارآمد تنظیم کنید، میتوانید به موتورهای جستجو، به ویژه Googlebot، اعلام کنید که از بررسی برخی صفحات صرفنظر کنند. به این ترتیب، میتوانید به رباتها بگویید که کدام صفحات برای شما اولویت ندارند و بهتر است آنها را نادیده بگیرند. مطمئناً شما هم نمیخواهید که رباتهای خزنده گوگل، وقت و منابع سرور شما را صرف مشاهده و ایندکس محتوای تکراری یا کمارزش کنند.
استفاده صحیح از فایل robots.txt به رباتهای جستجو کمک میکند تا Crawl Budget سایت شما را بهینه مصرف کنند. این ویژگی، اهمیت فایل robots.txt را در بهبود سئو سایت بهشدت افزایش میدهد.
برای درک بهتر سوال سئو چیست میتوانید به مهام سر بزنید. همچنین در مهام متوجه میشوید که دیجیتال مارکتینگ نیز به مجموعهای از روشها و ابزارها گفته میشود که با هدف جذب و تعامل با کاربران آنلاین به کار گرفته میشوند و یکی از مؤثرترین استراتژیها در دیجیتال مارکتینگ، بازاریابی محتوا است که با تولید محتوای ارزشمند و مرتبط، به جذب مخاطبان هدف کمک میکند و جایگاه سایت را در موتورهای جستجو تقویت میکند.
با این حال، توجه داشته باشید که نبود فایل robots.txt به معنای جلوگیری از خزش نیست. در واقع، اگر این فایل در سایت شما وجود نداشته باشد، رباتهای گوگل بدون محدودیت به تمام بخشهای در دسترس وبسایت دسترسی خواهند داشت و تمامی محتوا را بررسی میکنند.
برای بهرهمندی از مزایای کامل، پیشنهاد میکنیم از مشاوره سئو و همچنین شرکت در یک دوره آموزش سئو استفاده کنید تا بهترین استراتژیها را برای تنظیم و بهینهسازی فایل robots.txt سایتتان بیاموزید. علاوه بر این، آشنایی با مهارتهای مرتبط در دوره آموزش طراحی سایت میتواند به شما کمک کند تا کنترل بیشتری بر جنبههای فنی وبسایت خود داشته باشید.
حالا بیایید به سراغ آموزش نحوه استفاده از فایل robots.txt برویم. اما پیش از آن، لازم است با محدودیتهای این فایل آشنا شویم.
فایل Robots محدودیتهایی دارد که باید بدانید.
دستورات فایل robots.txt لزوماً برای تمامی رباتهای موتورهای جستجو به یک شکل عمل نمیکنند. اینکه آیا یک ربات از این دستورات پیروی کند یا نه، به سیاستهای آن موتور جستجو بستگی دارد. برای مثال، ممکن است رباتهای گوگل دستورات را رعایت کنند، اما ربات موتورهای جستجوی دیگر مانند یاندکس یا بینگ از آن پیروی نکنند. به همین دلیل، بهتر است دستورالعملهای هر موتور جستجو را مطالعه کنید تا مطمئن شوید که دستورات شما برای تمامی موتورهای جستجو بهدرستی کار میکنند.
امکان دارد که رباتهای مختلف حتی متعلق به یک موتور جستجو، دستورات فایل robots.txt را به شکل متفاوتی تفسیر کنند. برای مثال، ممکن است یکی از رباتهای گوگل دستوری را اجرا کند، در حالی که ربات دیگری از همان دستور پیروی نکند. این تفاوتها میتواند منجر به رفتارهای متفاوت در خزش و ایندکس صفحات وبسایت شود.
حتی اگر با استفاده از فایل robots.txt دسترسی رباتها به صفحهای را محدود کرده باشید، باز هم ممکن است گوگل آن صفحه را ایندکس کند و در نتایج جستجو نمایش دهد. این ایندکس شدن میتواند از طریق نقشه سایت (sitemap) یا از طریق لینکهایی که از دیگر صفحات و سایتها به این صفحه داده شده، رخ دهد.
پیشنهاد میکنم سری هم به مقاله عصاره لینک چیست؟ از مهام بزنید.
اگر صفحات سایت خود را در فایل robots.txt بهعنوان «noindex» مشخص کنید، باز هم امکان نمایش آنها در نتایج جستجو وجود دارد. گوگل ممکن است با استفاده از انکر تکستهای لینکها و سایر سیگنالها به آن صفحه رتبه دهد و در نتایج جستجو نشان دهد. معمولاً این صفحات بدون توضیحات متا در نتایج جستجو ظاهر میشوند، زیرا گوگل محتوای صفحه و متا توضیحات را ایندکس نکرده است.
خبر خوب برای شما عزیزانی که در مشهد زندگی میکنید. آژانس مهام با سابقه 7 ساله در حوزههایی نظیر طراحی سایت در مشهد و خدمات سئو در مشهد بعنوان بهترین آژانس بازاریابی محتوا در مشهد شناخته میشود.
در فایل robots.txt، چهار دستور اصلی وجود دارد که با استفاده از آنها میتوان نحوه دسترسی رباتها به بخشهای مختلف سایت را تنظیم کرد:
در ادامه توضیح میدهیم که هر یک از این دستورات چگونه استفاده میشوند.
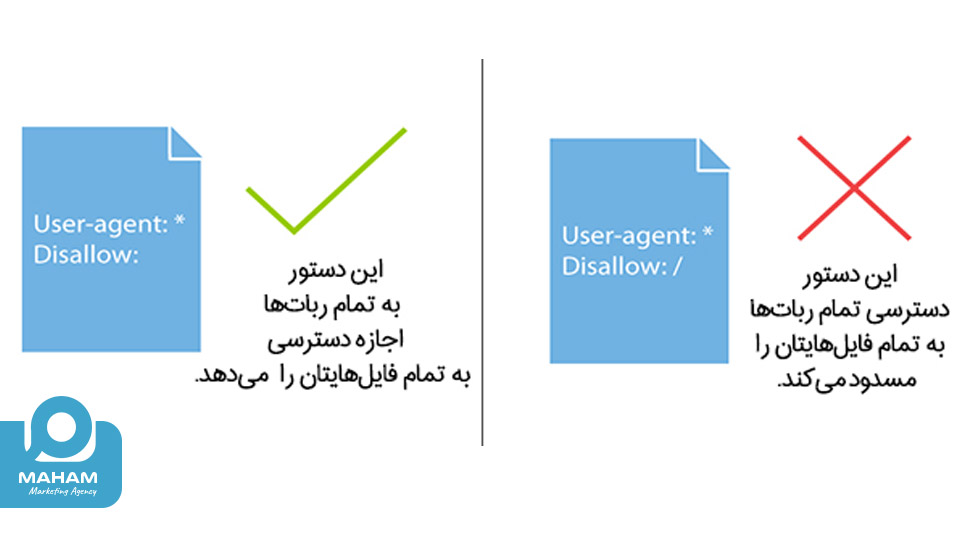
دستور User-agent برای مشخص کردن رباتی است که دستورات به آن اختصاص دارد. این دستور به دو شکل استفاده میشود:
User-agent: *
این دستور به این معنی است که تمامی رباتها باید از دستورات بعدی پیروی کنند.
User-agent: Googlebot
این دستور به این معنی است که دستورات تنها برای ربات گوگل قابل اجرا است.
دستور Disallow به رباتها اعلام میکند که به کدام بخشهای سایت نباید دسترسی داشته باشند. به عنوان مثال، اگر نمیخواهید موتورهای جستجو، تصاویر سایت را ایندکس کنند، میتوانید تمام تصاویر را در یک پوشه (مانند photos) قرار دهید و آن را غیرقابل دسترس کنید:
User-agent: *Disallow: /photos
دستور بالا به رباتها میگوید که وارد پوشه photos نشوند. در این دستور، «User-agent: *» تمامی رباتها را هدف قرار میدهد و «Disallow: /photos» به آنها اعلام میکند که از این پوشه دوری کنند.
نکته: نیازی نیست آدرس کامل صفحهها را در مقابل دستورات Disallow و Allow بنویسید.
ربات گوگل دستوری به نام Allow را درک میکند که به شما امکان میدهد یک فایل خاص را در پوشهای که دسترسی آن برای رباتها بسته شده، باز کنید. به عنوان مثال، اگر میخواهید به یک تصویر خاص در پوشه photos اجازه دسترسی دهید:
User-agent: *Disallow: /photosAllow: /photos/novin.jpg
این کد به ربات گوگل میگوید که با وجود عدم دسترسی به کل پوشه photos، اجازه دارد فایل novin.jpg را مشاهده و ایندکس کند.
گوگل چندین روش برای دسترسی به نقشه سایت فراهم کرده است و یکی از این روشها این است که آدرس نقشه سایت را در فایل robots.txt قرار دهید. البته الزامی برای ارائه نقشه سایت از طریق فایل robots.txt وجود ندارد و میتوانید این آدرس را مستقیماً در ابزار سرچ کنسول گوگل وارد کنید.
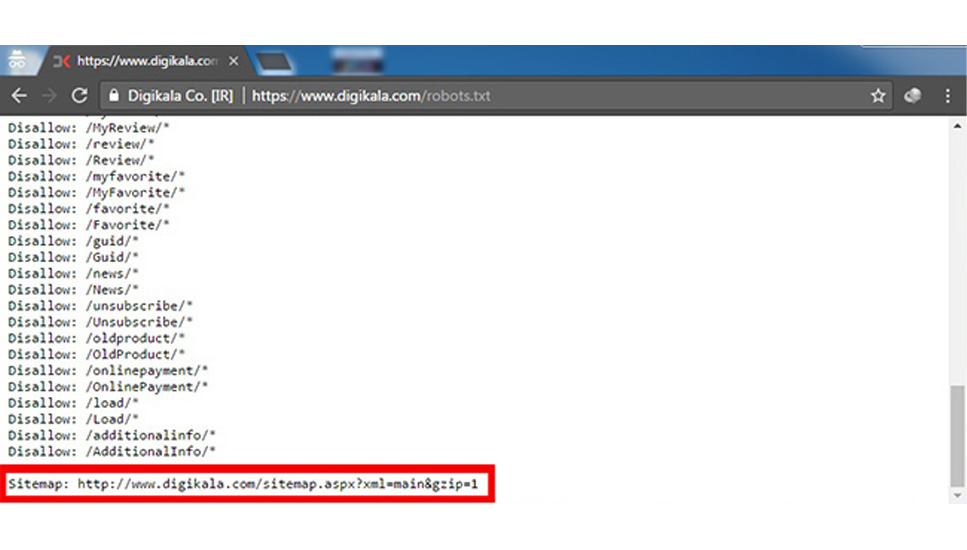
برای مثال:
Sitemap: https://example.com/sitemap.xml
در ادامه، نحوه ایجاد فایل robots.txt، محل قرارگیری آن در سایت و چگونگی تست دسترسی رباتها به این فایل را توضیح خواهیم داد.
اگر علاقمندید که نگاهی به فایل robots.txt سایت خود یا هر سایت دیگری بیندازید، پیدا کردن آن کار دشواری نیست.
برای مشاهده این فایل، کافی است آدرس سایت مورد نظر را در مرورگر خود وارد کنید (مثلاً maham.marketing یا هر سایت دیگر) و سپس عبارت /robots.txt را به انتهای URL اضافه کنید.
با انجام این کار فایل robots را در مرورگر میبینید. درست مثل تصویر زیر.
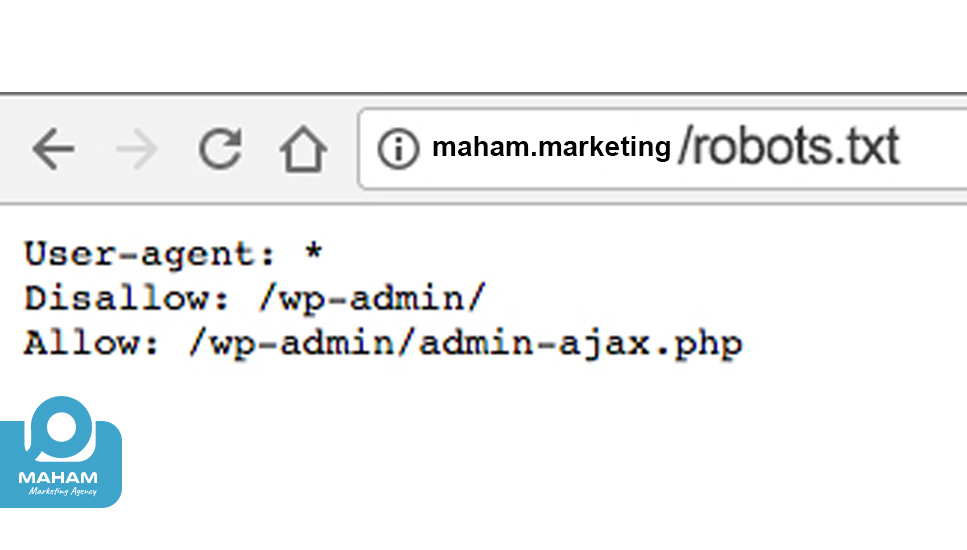
با بررسی فایلهای robots.txt سایتهای دیگر میتوانید از دستورات و ساختار آنها برای سایت خود الگوبرداری کنید.
فایل robots.txt در دایرکتوری ریشه (Root) سایت شما قرار دارد. برای دسترسی به این دایرکتوری، وارد حساب هاستینگ وبسایتتان شوید و به بخش مدیریت فایلها بروید.
به احتمال زیاد با چنین صفحهای روبرو خواهید شد.
پس از پیدا کردن فایل robots.txt، آن را برای ویرایش باز کرده، دستورات جدید را اضافه کرده و تغییرات را ذخیره کنید.
نکته: ممکن است فایل اصلی robots.txt را در دایرکتوری ریشه وبسایت پیدا نکنید. این اتفاق به این دلیل است که برخی سیستمهای مدیریت محتوا بهطور خودکار یک فایل robots.txt مجازی تولید میکنند. در این شرایط، بهتر است خودتان یک فایل robots.txt جدید ایجاد کنید تا همیشه به آن دسترسی مستقیم داشته باشید.
برای ساختن فایل robots.txt به هیچ نرمافزار خاصی نیاز ندارید؛ یک ویرایشگر ساده متنی مانند Notepad در ویندوز یا هر ویرایشگری که امکان ذخیره فایل با فرمت TXT را داشته باشد، کافی است. هنگام ایجاد فایل robots.txt، حتماً از فرمت UTF-8 برای انکودینگ استفاده کنید.
ابتدا یک فایل جدید با فرمت TXT ایجاد کنید و سپس آن را باز کنید. طبق دستورالعملهای مربوطه، دستورات مورد نظر را در آن وارد کنید.
در ادامه، میتوانید یک نمونه از فایل robots.txt ساده را مشاهده کنید.
فایل robots.txt باید در دایرکتوری ریشه (Root) سایت شما قرار بگیرد، یعنی دقیقاً در پوشه اصلی سرور میزبانی وبسایت. به این ترتیب، آدرس فایل به شکل زیر خواهد بود:
https://www.example.com/robots.txt
اگر این فایل در پوشه دیگری مانند pages قرار گیرد، رباتهای گوگل قادر به دسترسی به آن نخواهند بود. برای مثال:
https://example.com/pages/robots.txt
فرقی نمیکند که از سرور اختصاصی، اشتراکی یا مجازی استفاده میکنید؛ فقط مطمئن شوید که فایل robots.txt را در دایرکتوری اصلی سایت بارگذاری کردهاید.
برای مشاهده فایل robots.txt هر سایتی، کافی است عبارت /robots.txt را به انتهای URL آن سایت اضافه کنید.
شاید برای شما جالب باشد که بازاریابی محتوا چیست؟ بازاریابی محتوا یک استراتژی کلیدی در بهبود سئو است که با تولید محتوای ارزشمند و مرتبط، به بهبود رتبه سایت شما در الگوریتمهای گوگل کمک میکند.
برای اطمینان از اینکه یک صفحه یا فایل خاص توسط فایل robots.txt مسدود شده است و همینطور برای بررسی دسترسیپذیری فایل robots.txt، میتوانید از ابزار تستکننده در سرچ کنسول گوگل استفاده کنید.
اگر وبسایت خود را به سرچ کنسول گوگل متصل کردهاید، با باز کردن این ابزار تست از شما خواسته میشود که سایت مورد نظر را انتخاب کنید. پس از انتخاب، به صفحهای هدایت میشوید که محتوای فعلی فایل robots.txt که گوگل دریافت و بررسی کرده را نمایش میدهد. در این صفحه، امکان ویرایش فایل نیز وجود دارد و با زدن دکمه Submit صفحهای برای شما باز خواهد شد.
در این صفحه سه دکمه به شما نمایش داده میشود:
در نهایت، دکمه Submit را بزنید تا گوگل فایل جدید را دریافت و بررسی کند. پس از موفقیتآمیز بودن این مراحل، تاریخ و ساعت آخرین بررسی فایل robots.txt بهروزرسانی خواهد شد. برای اطمینان بیشتر میتوانید دوباره از همین ابزار استفاده کنید.
این ابزار نمیتواند فایل robots.txt را مستقیماً ویرایش کند؛ پس از کلیک روی Submit، پنجرهای ظاهر میشود که از شما میخواهد فایل جدید ویرایششده را دانلود کرده و به جای فایل قبلی در سرور خود جایگزین کنید.
اگر بخواهید صفحات مشخصی را نیز تست کنید، کافی است آدرس صفحه را در نوار پایینی وارد کرده و ربات گوگلی که مد نظر دارید را انتخاب کنید. هر بار که دکمه Test را بزنید، بلافاصله به شما نشان میدهد که آیا به آن ربات اجازه دسترسی دادهاید یا خیر.
بهعنوان مثال، میتوانید بررسی کنید که آیا ربات گوگل برای تصاویر به یک صفحه خاص دسترسی دارد یا خیر. ممکن است به ربات اصلی گوگل برای دسترسی به صفحه اجازه داده باشید، اما ربات تصاویر اجازه دسترسی و نمایش تصاویر را در نتایج جستجو نداشته باشد.
گوگل اعلام کرده است که استفاده از دستورات noindex و disallow در فایل robots.txt برای حذف کامل صفحات از نتایج جستجو کافی نیست. برای حذف یک صفحه از نتایج جستجو، باید دستور noindex را مستقیماً در همان صفحه قرار دهید.
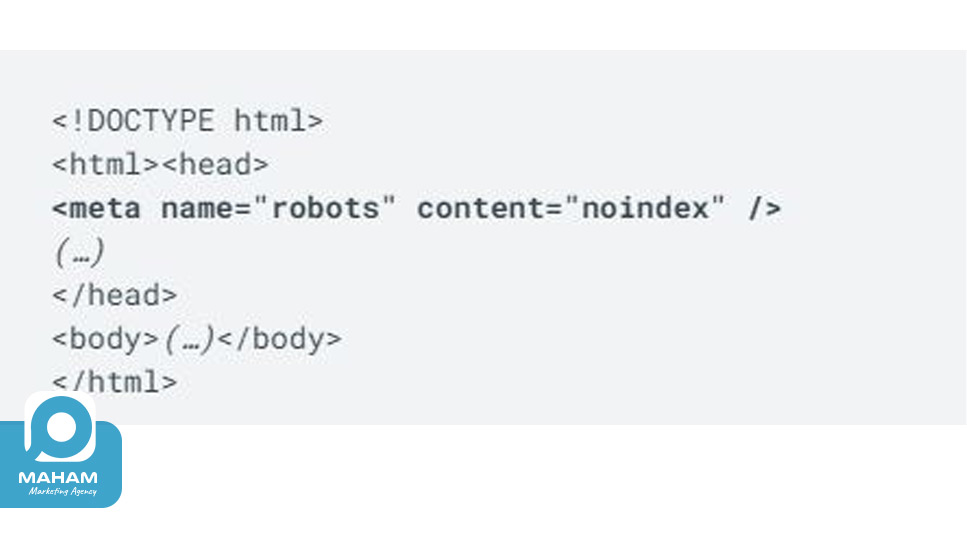
سادهترین روش برای حذف یک صفحه از نتایج جستجو، استفاده از متا تگهای noindex در بخش head صفحه است. برای این کار، میتوانید کد HTML صفحه را مستقیماً ویرایش کرده یا از افزونهها برای افزودن دستور noindex استفاده کنید؛ در واقع، افزونهها نیز تنها همین کد را به بخش head صفحه اضافه میکنند.
اگر با کدهای HTML کمی آشنایی دارید، میدانید که هر صفحه شامل دو بخش head و body است. دستور noindex باید در قسمت head قرار بگیرد تا به رباتها اعلام کند که این صفحه در نتایج جستجو نمایش داده نشود.
در این مقاله، هرآنچه که برای کنترل رباتهای جستجوگر گوگل و مدیریت دسترسی آنها به صفحات سایت لازم بود، به زبان ساده توضیح دادیم. فایل robots.txt را کافی است تنها یکبار آماده کنید و پس از آن دیگر نیازی به ویرایش آن نخواهید داشت، مگر اینکه تغییرات بزرگی در ساختار سایت ایجاد کنید.
فایل Robots.txt یک فایل متنی است که در ریشه سایت قرار میگیرد و به رباتهای موتورهای جستجو اعلام میکند کدام صفحات یا بخشهای سایت را باید یا نباید خزش کنند. این فایل به شما کمک میکند تا دسترسی رباتها به قسمتهای خاصی از سایت را مدیریت کنید و از بار اضافی روی سرور جلوگیری نمایید.
نبود فایل Robots.txt باعث نمیشود که سایت شما به درستی توسط رباتهای جستجو خزش نشود. در این صورت، رباتها بدون هیچ محدودیتی تمام صفحات سایت را بررسی میکنند. اما اگر قصد دارید دسترسی رباتها به بخشهای خاصی از سایت را محدود کنید، بهتر است از این فایل استفاده کنید.
برای این کار، میتوانید دستور Disallow را در فایل Robots.txt استفاده کنید. به این ترتیب، صفحات یا پوشههایی که نمیخواهید توسط رباتهای گوگل بررسی شوند، از دسترس آنها خارج میشوند.













2 پاسخ
سلام وقت بخیر عالی نوشته بودیدخیلی خوب توضیح دادید که فایل robots.txt چطور میتونه به مدیران سایتها کمک کنه تا رفتار رباتها رو مدیریت کنند. سوالی که دارم اینه که آیا فایل robots.txt میتونه تأثیر مستقیمی روی سئو داشته باشه یا بیشتر برای بهینهسازی عملکرد سایت در برابر رباتهاست؟
سلان وقتتون بخیر باشه، مرسی از کامنت خوبتون
در پاسخ سوالتون باید بگم که فایل robots.txt بهطور مستقیم بر رتبهبندی سایت در موتورهای جستوجو تأثیر نمیذاره، اما با مدیریت صحیح رفتار رباتها میتونه به بهینهسازی ساختار سایت و جلوگیری از ایندکس شدن صفحات بیارزش کمک کنه. اینجوری، به موتور جستوجو کمک میکنید تا منابع سرور رو روی صفحات مهمتر متمرکز کنه و سرعت ایندکس بهتری داشته باشید.